Articles
- Page Path
- HOME > Sci Ed > Volume 11(1); 2024 > Article
-
Review
Trends in research on ChatGPT and adoption-related issues discussed in articles: a narrative review -
Sang-Jun Kim

-
Science Editing 2023;11(1):3-11.
DOI: https://doi.org/10.6087/kcse.321
Published online: December 18, 2023
Korea Research Institute of Bioscience and Biotechnology, Daejeon, Korea
- Correspondence to Sang-Jun Kim sjkim@kribb.re.kr
• Received: August 1, 2023 • Accepted: September 15, 2023
Copyright © 2024 Korean Council of Science Editors
This is an open access article distributed under the terms of the Creative Commons Attribution License (https://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
- 3,645 Views
- 124 Download
Abstract
- This review aims to provide guidance for those contemplating the use of ChatGPT, by sharing research trends and evaluation results discussed in various articles. For an objective and quantitative analysis, 1,105 articles published over a 7-month period, from December 2022 to June 2023, following the release of ChatGPT were collected. These articles were sourced from PubMed, Scopus, and Web of Science. Additionally, 140 research articles were selected, including archived preprints and Korean articles, to evaluate the performance of ChatGPT. The analysis of research trends revealed that related communities are rapidly and actively responding: the educational community is redefining its directions, the copyright and patent community is monitoring lawsuits related to artificial intelligence creations, the government is establishing laws to regulate and prevent potential harm, the journal publishing community is setting standards for whether artificial intelligence can be considered an author, and the medical community is publishing numerous articles exploring the potential of ChatGPT to support medical experts. A comparative analysis of research articles on ChatGPT’s performance suggests that it could serve as a valuable assistant in human intellectual activities and academic processes. However, its practical application requires careful consideration to overcome certain limitations. Both the general public and researchers should assess the adoption of ChatGPT based on accurate information, such as that provided in this review.
- Background and rationale
- ChatGPT, a portmanteau of “chat” and “generative pretrained transformer (GPT),” is a conversational artificial intelligence (AI) chatbot developed by OpenAI (https://openai.com/), with support from Microsoft. From December 2022 to January 2023, it garnered over 100 million early users. ChatGPT generates sophisticated responses to prompts in various fields, such as writing poems and essays, creating examination questions, providing common knowledge, composing music, gaming, and programming. This has once again highlighted the advancement of AI technology, following AlphaGo’s victory (DeepMind) over Sedol Lee, a Korean Go player. ChatGPT, which has gained significant attention in a short period, is a deeply learned natural language processing model. It probabilistically predicts the next words in a given sentence, based on Google’s Transformer. ChatGPT is built on GPT-3.5, a large language model, and is fine-tuned using supervised learning with human AI trainers and reinforcement learning from human feedback. Unlike other chatbots, ChatGPT retains what it has learned and the context of conversations and questions, enabling it to generate detailed and logical answers akin to a human. It is also designed to avoid providing false answers, but it occasionally generates inaccurate and absurd responses. ChatGPT does have some learning limitations. It struggles to learn about events and knowledge post-September 2021 and can generate dangerous and unethical responses due to algorithmic bias. These issues have sparked debates about its adoption.
- The global competition among information technology (IT) companies to lead in AI technology has intensified, despite the partial limitations of ChatGPT. In February 2023, Google unveiled Bard, based on LaMDA, and Meta released LLaMA, followed by the open-source LLaMA 2 in July. This allowed anyone to create AI using publicly available codes and models. In March 2023, China’s Baidu released Ernie Bot, Korea’s Naver launched HyperCLOVA X in August 2023, and Apple announced in July 2023 that it was developing AppleGPT. The advent of ChatGPT has transformed the era of Google-style webpage searches into an era where AI-generated results supplement traditional searches. This is achieved by using prompt sentences instead of keyword inputs, multimodal queries instead of text-only searches, and providing written answers instead of displaying webpages. Following the launch of the paid premium ChatGPT Plus in February 2023 and the release of GPT-4 in March 2023, ChatGPT expanded its use by providing an application programming interface (API) and adding plugins both internally and externally. The release of a dedicated iOS app in May 2023 further broadened its use. The early release of GPT-4 was particularly surprising. Unlike the text answers of GPT-3.5, which formed the basis of ChatGPT, GPT-4 is a multimodal platform capable of interpreting images (modality). This represents a significant technological leap in a short period of time. According to OpenAI’s data on GPT-4’s performance [1], the accuracy of English has improved from 70.1% to 85.5%. Korean has seen significant improvements, with an accuracy rate of 77%. Policy responses to sensitive information have increased by 29%, while unacceptable responses have been reduced by 82%, thereby reducing hallucinations. However, even with GPT-4-based ChatGPT, the limitations of GPT-3.5 [2] (e.g., writing plausible-sounding but incorrect or nonsensical answers, sensitivity to tweaks in input phrasing or repeated attempts at the same prompt, verbosity and overuse of certain phrases, guessing user intent for ambiguous queries, and occasionally responding to harmful instructions or exhibiting biased behavior) remain. Although OpenAI has acknowledged these issues, they continue to pose challenges for GPT-4.
- In the 7 months following the launch of ChatGPT, the scientific community has produced a wide array of articles. These pieces, which range from breaking news and brief opinions to suggestions and proposals, primarily focus on the advantages and disadvantages observed during the initial adoption phase, with testimonials serving as the main source of information rather than traditional research data. Up until April 2023, articles related to ChatGPT were predominantly found on PubMed, which includes articles more rapidly than other databases. However, starting in May 2023, the number of ChatGPT-related articles began to rise in Scopus and the Web of Science (WoS), both of which are notable bibliographic databases. The release of GPT-4, APIs, and plugins has further complicated the assessment of ChatGPT’s performance, making it more challenging to accurately judge its quality. From a user’s perspective, rather than a technological one, it is crucial to evaluate the precise quality of ChatGPT through a review of research articles that are grounded in research data.
- Objectives
- The exploding interest in ChatGPT since its launch could be more accurately assessed if its performance and quality were thoroughly summarized using only research articles that provide objective and quantitative data. To this end, a brief review was conducted of research trends and major responses to ChatGPT from articles related to ChatGPT obtained from major article databases. Their quality was then compared using research articles that met the criteria for objective performance evaluation. Consequently, this would assist the general public in assessing the quality of ChatGPT by sharing four key pieces of comparative information: the evaluation target and purpose, the data used, the main results, and the significance and value of these results. This review, which summarizes ChatGPT’s research trends and performance comparison, is intended to serve as a guide for those considering its adoption.
Introduction
- Ethics statement
- This was not a study with human subjects, so neither Institutional Review Board approval nor informed consent was required.
- Study design
- This was a database-based literature review.
- Data collection
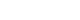
- To collect the target articles from major databases, [ChatGPT or “GPT-3.5” or “GPT-4”] was used as a search term, with the results limited to the title, abstract, and keywords fields. The search excluded conference articles and yielded 747 PubMed, 716 Scopus, and 539 WoS articles related to ChatGPT over a 7-month period until June 2023, as per the index date or database-inclusion date. The search results from these three major databases were downloaded into Microsoft Excel (Microsoft Corp). A crosscheck was then conducted against digital object identifiers (DOIs), PubMed IDs, and article titles to eliminate duplicates. This process resulted in an Excel list of 1,105 unique articles, which served as the research data. This list comprised 747 PubMed articles and 358 nonmedical articles from Scopus and WoS. All 1,105 articles underwent an initial review to identify the research trends of ChatGPT. For the purpose of comparing the issues related to the quality evaluation and adoption of ChatGPT, only 140 research articles were utilized, including 19 articles exclusively from Scopus and WoS. To mitigate the bias of regional responses and the 104 medical articles sourced from PubMed among the 140 research articles, 13 archived preprint articles were gathered from the Internet. Additionally, four Korean articles were sourced from the Korea Citation Index (https://www.kci.go.kr/) and ScienceOn (https://scienceon.kisti.re.kr/). These articles were restricted to those that included all four evaluation items: the evaluation object and purpose, the data used, the main results, and the significance and value of the results. These research articles were summarized in Suppl. 1. Fig. 1 illustrates the methodology and process of data collection for this review.
Methods
- Research trends of ChatGPT-related articles
- Shortly after the advent of ChatGPT, numerous opinion pieces were published across a variety of formats, including editorials, letters to the editor, news articles, correspondences, comments, and opinion pieces. Many of these early articles served as warnings, reiterating the limitations that OpenAI had officially acknowledged [2]. However, there were also many advocates who saw potential for diverse academic applications. From a pool of 1,105 articles, it is possible to discern broad research trends based on their publication patterns, albeit in an incomplete manner. In the following analysis, counts and percentages are calculated after excluding articles lacking detailed information.
- Among 587 journals, Cureus had a high concentration of 82 articles, with a special issue focusing on ChatGPT, followed by Annals of Biomedical Engineering, Nature, Aesthetic Surgery Journal, Radiology, Library Hi Tech News, and International Journal of Surgery. Among 134 publishers, which were grouped by the same criteria as in a previous study [3], Springer, which publishes Cureus, was the top publisher, followed by Elsevier, Taylor & Francis, Wiley, Oxford University Press, MDPI, and Sage. Of the 716 articles with publication status information, 226 were accepted articles, articles in press, and advanced prints, and 490 were final publications. Of the 518 articles with publication date, four were published in December 2022, 15 in January, 38 in February, 96 in March, 124 in April, 143 in May, and 98 in June 2023. The temporary decrease in June was presumed due to a time lag reflecting articles that had not yet been included in the databases. The language used in the 868 articles was mostly English, and there were only 31 articles in 10 other languages.
- Of the 868 articles identified in Scopus and WoS, research articles were the most prevalent, accounting for 43.9%. Letters comprised 19.5%, editorials 17.4%, notes 8.6%, reviews 5.8%, and other types of articles made up the remaining 2.6%. This suggests a significant number of opinion-oriented articles. In 537 articles, it was found that 36 had no references, 98 had between 1–5, 125 had between 6–10, 112 had between 11–20, 52 had between 21–30, and 114 had 31 or more. The lower number of references in some articles, particularly those with fewer than five, is likely attributable to the high number of opinion pieces, which typically do not rely on research data as heavily as research articles do. In terms of subject areas, of the 935 articles, 668 were in the medical field, 156 in the natural sciences, 55 in education, 46 in the social sciences, and 10 in the humanities. While the medical field was dominant, there was also significant interest in the use of ChatGPT in the education community. Excluding tentative Bronze and Green open access (OA) articles, there were 263 Gold OA and 85 Hybrid OA articles. However, only 31.5% of the articles were OA, which is lower than the 38.3% estimated in a previous study based on the 2021 Journal Citation Reports [3].
- The impact of ChatGPT on the field of education has been significant, as evidenced by the volume of articles on the subject. This has elicited a variety of responses. Elementary, middle, and high schools have been contemplating educational strategies, including countermeasures, to address students’ overreliance on ChatGPT for essay and assignment preparation [4]. Universities have been issuing guidelines for the use of AI tools in coursework, writing, and assignments, while also promoting ethical writing to prevent plagiarism [4]. The current status of ChatGPT has been easily ascertained through special issues of some journals, including 43 articles in International Journal of Information Management, 32 articles in IEEE Transactions on Computational Social Systems, and eight articles in Library Hi Tech News.
- Meanwhile, a major point of contention in the realms of copyright and patent law is whether AI can hold these rights. The consensus in many countries is negative. For AI products to qualify for copyright, they must be capable of expressing thoughts and feelings akin to human authors and demonstrate a minimum level of creativity. Separate from this, copyright violations related to data used in AI training have been the subject of litigation. Some writers and creators have taken legal action against copyright infringements and the industry’s excessive reliance on AI since the emergence of ChatGPT. The multinational lawsuits over DABUS, an AI that generates artistic concepts, have also raised concerns about whether it can be granted inventor status with patent rights, particularly since the advent of ChatGPT [5]. Although many countries have denied patent eligibility for AI-related inventions, excluding ChatGPT, some have granted patent rights. Beyond copyright and patent laws, there is also interest in legal regulations and the establishment of AI-related ethical standards in anticipation of societal issues arising from the proliferation of generative AI like ChatGPT. The European Union (EU)’s AI Act, the most advanced of AI-related legal regulations, classifies AI models according to risk level. It mandates that businesses dealing with high-risk AI disclose their algorithmic operating principles, excluding trade secrets [6].
- The educational community has been abuzz with the use of ChatGPT for student learning, and the journal publishing industry has been quick to respond to the release of ChatGPT. The primary concern is the issue of AI authorship and the acceptance of its use [7]. Guidelines for AI in the journal publishing industry existed even before the advent of ChatGPT, but there is a need for these to be updated and revised as the use of ChatGPT expands. According to the guidelines of relevant organizations such as the International Committee of Medical Journal Editors (ICMJE) [8], World Association of Medical Editors (WAME) [9], American Medical Association (AMA) [10], Committee on Publication Ethics (COPE) [11], and STM [12], major publishers like Elsevier [13], Springer [14], and Wiley [15] have taken a similar stance. They state that when ChatGPT-style AI is used, authors must acknowledge its use under their own responsibility, but AI itself cannot be an author.
- The guidelines related to ChatGPT were derived from the aforementioned sources, and the common points have been summarized for this review. First, AI authorship is not allowed: AI tools cannot be considered authors, because they are not accountable for their works and lack legal personality. Second, human authors must take full responsibility: if an AI tool is used in the article, the human authors must fully accept responsibility for the accuracy of the results. Third, it is necessary to ensure proper disclosure of the AI used: if an AI tool has been utilized in the writing of the article, pertinent details such as its name, version, and manufacturer must be disclosed in appropriate sections such as Methods or Acknowledgments.
- While many publishers and organizations seem to share a similar viewpoint, Science [16] takes a particularly stringent stance, asserting that AI tools like ChatGPT cannot be used, and any violation of this policy constitutes scientific misconduct [7]. This journal has a strong policy: AI cannot be an author of an article; therefore, texts generated by AI, machine learning, or similar algorithmic tools cannot be used in an article without explicit permission from the editor, and any accompanying figures, images, and graphics cannot be the product of AI. ChatGPT itself has stated [17], “ChatGPT cannot ensure the accuracy, validity, and reliability of scientific claims and findings. …. [I]t should not be relied upon for writing academic scientific manuscripts for publication.” However, the policy regarding AI authorship is still in its early stages, and some journals lack clear criteria. As such, articles that listed ChatGPT as an author were sought. While PubMed and Scopus yielded no results, WoS classified two as group authors, ScienceDirect had two (including one that was later removed as a co-author), and ScienceOn, which focuses on preprints, OA, and Korean articles, had six articles. These 10 articles are depicted in Fig. 2.
- ChatGPT adoption issues discussed in research articles
- The emergence of ChatGPT has sparked concerns about job losses in intellectual professions, including those of novice programmers, rather than in physical labor roles. However, of the 140 research articles examining the quality and performance of ChatGPT, the medical profession demonstrated the most interest, accounting for over half of the articles. The performance evaluation of ChatGPT was broadly divided into the following categories: passing various tests (e.g., professional certifications and university exams), applicability in medical practice (e.g., medical school exams, clinics and doctors, patients and nursing), and writing support. In the 140 research articles, the key findings from these three categories were succinctly summarized and compared in the Suppl. 1.
- Among professional licensing exams for doctors, residents, lawyers, and law school admissions, GPT-3.5 came close to passing the United States Medical Licensing Examination (USMLE), but its performance was below the test-taker average. However, GPT-4 [18] showed improved performance, scoring above the average, a result that was also confirmed by the Japanese medical examination. There were reports of inconsistent performance results on various exams for medical specialists, which require more experience among doctors. Consequently, the results ranged from failing to nearly passing on GPT-3.5, and from passing to exceeding average scores on GPT-4. The German medical specialist qualification exam presented a borderline passing case, but the performance was close to passing the Taiwanese pharmacist exam. The evaluation also demonstrated that ChatGPT was capable of human-level performance on the bar exam and the certified public accountant (CPA) exam. It managed to just pass the Law School Admission Test (LSAT) in the United States, but the Korean equivalent, the Legal Education Eligibility Test (LEET) [19], showed large disparities depending on the type of questions. Overall, performance on the professional licensing exams was generally satisfactory, with some areas falling below the human average, but in some instances, GPT-4 exceeded the human average [20].
- In terms of college entrance, coursework, and graduation-related exams, the performance in chemistry and math, which require complex solution processes, was somewhat disappointing. However, in other university exams, ChatGPT demonstrated a level of competitiveness comparable to humans. The results varied depending on the subject, evaluation method, and evaluator, ranging from barely passing [21] to surprisingly successful results [22]. Thus, ChatGPT has been assessed in various university examinations. While the evaluations varied by course, it was deemed to have abilities similar to humans in many areas, with a few exceptions. Nevertheless, with the advent of GPT-4, it is anticipated that some of the performance shortcomings of GPT-3.5 can be overcome.
- GPT-3.5 has been evaluated across a wide range of medical course exams, too numerous to be individually categorized within university examinations. The performance levels and results varied depending on the specific evaluation case, ranging from unlikely to pass [23], partially passable, fully passable, passable and above the human average, and sufficient to prepare for medical specialist exams. ChatGPT had also been evaluated for its ability to generate specialized knowledge in the medical field. Based on these evaluations, it shows promise as a potential tool for medical education. Interestingly, while GPT-3.5’s scores in parasitology were significantly lower than the average for Korean medical students [24], inconsistent results have been reported for GPT-4, with one article suggesting an unlikely passable level [25] and another indicating that GPT-4’s performance was sufficient to prepare for medical specialist exams [26].
- Evaluations of ChatGPT’s performance in healthcare, a field that is currently a focal point of academic debate, have yielded mixed results. While some evaluations have been satisfactory, the general consensus is that it is less competent than human doctors. The results varied widely, with performance fluctuating based on the topic, instances of incompetence [27], partially acceptable performance, acceptable performance with shortcomings [28], and even instances where ChatGPT outperformed human doctors [29]. Given that accuracy and reliability in diagnosis are fundamental and essential in clinical practice and medical information, it was determined that while ChatGPT may offer some utility and benefits, its use should be approached with caution due to potential risks. Particularly in areas requiring intricate and complex knowledge, such as human anatomy and pharmacology, ChatGPT’s limitations were evident. Many articles have suggested that ChatGPT should be viewed as a tool to enhance and support the work of healthcare professionals, rather than as a replacement for human experts, thereby improving patient care and opportunities. Even within the medical field, a sector that requires extensive knowledge and is closely tied to human life, the potential for using ChatGPT to assist medical experts is being explored with caution, yet with a high degree of interest and enthusiasm.
- In the areas of patient care and nursing, where the level of expertise and knowledge required is likely to be less extensive than that required of a doctor, ChatGPT has shown inadequate performance [30], helpful performance, and satisfactory performance [31] compared to human nursing experts. Although most evaluations deemed it satisfactory for patient care and generating responses to patient inquiries, there was a general agreement that the immediate and direct implementation of ChatGPT in a nursing setting should be approached with the same caution as with physicians. Consequently, there is significant room for improvement in the use of ChatGPT for the development of medical information and services provided to patients before and after hospital visits.
- In the realm of writing evaluations, both positive trends and areas of concern have been identified. Some promising results have been observed in areas such as topic selection and generation, report writing, effective content summarization, proficient translation skills, improved grammatical writing, and the creation of complex writing that reviewers struggle to identify as AI-assisted [32]. There is also potential for partial automation in grading writing scores. However, issues have been detected with the generated responses, including evidence falsification and inadequate referencing [33]. Therefore, it appears that the use of ChatGPT in writing is likely to become more prevalent, as many researchers have found it useful for various purposes. However, addressing the issue of paraphrasing to avoid plagiarism detection—by using different expressions with the same meaning—is not straightforward. When AI tools like ChatGPT are readily available for written output, the probability of poor and unethical products being published in certain predatory journals increases [26]. This situation calls for a global response and societal attention. If AI chatbots are used to rapidly generate low-quality manuscripts with minimal human involvement and intervention, the resulting surge in poor-quality publications will lead to a significant waste of societal resources in verifying the authenticity of the generated content. Alongside the trend of rapid publication in the style of MDPI [3], as more articles are submitted using ChatGPT-generated results, all stakeholders in the publishing industry—including publishers, editors, authors, and readers—face the potential waste of time in verifying authorship and authenticity. Therefore, writing evaluators and article reviewers are looking to AI-product detection tools for technical support and robust performance. While some of these tools have been evaluated as effective [34], a deeper look revealed technical limitations [32]. As such, these tools should be used with caution.
Results
Publishing trends in some of the 1,105 articles
The nonmedical community’s response to ChatGPT
Authorship issue and common guidelines for AI-generated articles
Passing various tests
Professional certifications
University exams
Applicability in medical practice
Medical school exams
Clinics and doctors
Patients and nursing
Writing support
- As previously discussed, determining whether to utilize ChatGPT can be challenging due to the varying methods and standards used to evaluate its performance and quality. Despite some issues identified in the evaluation results, the majority of opinions lean towards the positive, particularly regarding the use of ChatGPT to support and enhance human intellectual activities. Upon assessing ChatGPT’s performance across various exams, it was found to surpass human-level proficiency in most cases, with only a few exceptions [25]. Further improvements are anticipated with the introduction of GPT-4 [26]. While immediate implementation in clinical areas such as diagnosis may present challenges, the consensus is that ChatGPT is better suited to a supportive role rather than replacing medical experts entirely. The provision of patient information and the role of an information assistant were deemed to have minimal issues, and the most enthusiastic adoption is expected in these areas. However, while ChatGPT can assist humans with intellectual tasks, it also necessitates a new task: identifying and rectifying errors or issues in tasks that require precision. As machine AI begins to generate knowledge information, a domain previously exclusive to humans, we are faced with a new challenge. It is crucial to distinguish between human-generated and machine-generated content, a process that can be both time-consuming and costly. If ChatGPT is used to easily generate written content, significant social costs and disruptions could arise if measures are not promptly put in place to verify the file version, authorship, and authenticity of the generated content.
- Despite the impressive capabilities and benefits of ChatGPT, it is crucial to also focus on its drawbacks and limitations (e.g., hallucinations, copyright infringement concerns related to learning sources, plagiarism and copyright infringement concerns in the generated answers, time lag for further learning of new information after full learning, legal issues related to privacy and healthcare, and so on) [2]. There is a pressing need to develop ethical guidelines and legal frameworks for the use of generative AI. ChatGPT, which has sparked considerable social debate, is viewed and evaluated from a variety of perspectives, reflecting diverse interests and results. Therefore, the evaluation process needs to be refined and standardized to ensure that the performance and quality of AI are assessed consistently and fairly worldwide. The standardization of evaluation methods and criteria is vital, as different results may be obtained based on the number of prompts used in the performance evaluation, the specific prompts measured if multiple prompts are used, the version evaluated at a particular point in time, whether the evaluation is conducted in OpenAI’s or an external partner’s API or plugins environments, and how images are converted and evaluated in relation to the text. As highlighted in this review, these issues span multiple academic disciplines, not just one, making it extremely challenging to establish a universally accepted standardized evaluation method for ChatGPT, given the conflicting interests of various stakeholders in the academic community.
- Some performance evaluations of GPT-4 yielded mixed results, with near-perfect performance [22] and no improvement over GPT-3.5 in research idea generation [35], but GPT-4 is more robust and less problematic in performance. While OpenAI’s announcement [1] confirms that GPT-4 boasts many improvements over GPT-3.5. Still, a more accurate understanding of GPT-4’s capabilities will come from further performance evaluations based on this newer model. In this review, 140 research articles were examined to compare performance evaluations, but only 29 of these were based on GPT-4. This is a small number, given that GPT-4 was released just 3 months ago. However, as more evaluations are conducted using GPT-4, which reflects the latest technology, a clearer picture of its current state will emerge. In GPT-3.5, evaluations were limited and focused primarily on text, as the model’s ability to handle diagrams and pictorial information was limited. In contrast, GPT-4’s evaluation has become both easier and more complex due to its support for multimodal features. As GPT-3.5 and GPT-4 will coexist for the time being, distinguishing and judging the versions and environments used in AI evaluation has become an important issue.
- Conclusion
- In order to more accurately judge the performance and quality of ChatGPT, 1,105 articles were collected from major databases to understand related research trends. Additionally, 140 research articles were analyzed, including preprints and Korean articles, that dealt with performance evaluation using objective and quantitative methods, to examine issues related to ChatGPT’s adoption. In the 7 months following ChatGPT’s launch, more opinion-based articles were published than research articles. In response to the adoption of ChatGPT, the education community has been attempting to redirect educational strategies, the copyright and patent community has been on the lookout for lawsuits concerning the intellectual property rights of AI-generated works, and the government has been advocating for legal institutionalization to prepare for societal issues. In the journal publishing industry, standards for author recognition for AI use have been largely established, and the medical community has been actively producing numerous articles exploring the potential of using ChatGPT to support medical experts. Performance evaluations have shown that many articles recognize ChatGPT’s potential to serve as a useful aid for human intellectual activities and practical processes, such as medicine. As such, many believe that ChatGPT should not be resisted or its introduction delayed, but rather, it should be actively utilized as an assistant by overcoming its problems and limitations. Moreover, it is necessary for ChatGPT to improve its ability to present evidence-based references, similar to Scopus AI, as well as address the potential for hallucinations and copyright violations that may be inherent in generative chatbots without OpenAI disclosing the sources of learned information. Therefore, the general public, who should evaluate the usefulness and performance level of ChatGPT from a user’s perspective rather than a technical one, needs to respond with accurate information, as provided in this review. This review has limitations, including that the discrepancies in the information contained in major databases were not fully evaluated, and that it primarily summarizes the majority opinions from previous studies. Nevertheless, this review will be beneficial for academics and the general public considering the adoption of ChatGPT. If the numerous issues with ChatGPT can be improved, we may see the world evolve into a more advanced and convenient era of generative AI, rather than facing the downfall of humanity.
Discussion
-
Conflict of Interest
No potential conflict of interest relevant to this article was reported.
-
Funding
The author received no financial support for this work.
-
Data Availability
Dataset file is available from https://doi.org/10.7910/DVN/LMPTQH.
Dataset 1. List of 1,105 unique articles related to ChatGPT for this review.
Notes
-
Acknowledgements
- The author thanks Kay Sook Park, retired from ETRI, with whom the author has co-authored at six Science Editing journal articles, for her kind discussion and advice on English.
Supplementary Materials


- 1. OpenAI. GPT-4 [Internet]. OpenAI; 2023 [cited 2023 Jul 8]. Available from: https://openai.com/research/gpt-4.
- 2. OpenAI. Introducing ChatGPT [Internet]. OpenAI; 2022 [cited 2023 Jul 8]. Available from: https://openai.com/blog/chatgpt.
- 3. Kim SJ, Park KS. Publishing trends of journals and articles in Journal Citation Reports during the COVID-19 pandemic: a descriptive study. Sci Ed 2023;10:78-86.https://doi.org/10.6087/kcse.300. Article
- 4. Lo CK. What is the impact of ChatGPT on education? A rapid review of the literature. Educ Sci 2023;13:410. http://doi.org/10.3390/educsci13040410. Article
- 5. Ariyaratne S, Botchu R, Iyengar KP. ChatGPT in academic publishing: an ally or an adversary? Scott Med J 2023;68:129-30.https://doi.org/10.1177/00369330231174231. ArticlePubMed
- 6. Helberger N, Diakopoulos N. ChatGPT and the AI Act. Internet Policy Rev 2023;12:28. https://doi.org/10.14763/2023.1.1682. Article
- 7. Stokel-Walker C, Van Noorden R. What ChatGPT and generative AI mean for science. Nature 2023;614:214-6.https://doi.org/10.1038/d41586-023-00340-6. ArticlePubMed
- 8. International Committee of Medical Journal Editors (ICMJE). Defining the role of authors and contributors [Internet]. ICMJE; c2023 [cited 2023 Jul 8]. Available from: https://www.icmje.org/recommendations/browse/roles-andresponsibilities/defining-the-role-of-authors-and-contributors.html.
- 9. World Association of Medical Editors (WAME). Chatbots, generative AI, and scholarly manuscripts: WAME recommendations on chatbots and generative artificial intelligence in relation to scholarly publications [Internet]. WAME; 2023 [cited 2023 Jul 8]. Available from: https://wame.org/page3.php?id=106.
- 10. Flanagin A, Bibbins-Domingo K, Berkwits M, Christiansen SL. Nonhuman “authors” and implications for the integrity of scientific publication and medical knowledge. JAMA 2023;329:637-9.https://doi.org/1001/jama.2023.1344. ArticlePubMed
- 11. Committee on Publication Ethics (COPE). Authorship and AI tools [Internet]. COPE; 2023 [cited 2023 Jul 8]. Available from: https://publicationethics.org/cope-position-statements/ai-author.
- 12. STM. AI ethics in scholarly communication: STM best practice principles for ethical, trustworthy and human-centric AI; STM; 2021 https://www.stm-assoc.org/2021_05_11_STM_AI_White_Paper_April2021.pdf.
- 13. Elsevier. Publishing ethics: duties of authors [Internet]. Elsevier; c2023 [cited 2023 Jul 8]. Available from: https://beta.elsevier.com/about/policies-and-standards/publishing-ethics?trial=true#4-duties-of-authors.
- 14. Springer. Editorial policies [Internet]. Springer Nature; c2023 [cited 2023 Jul 8]. Available from: https://www.springer.com/gp/editorial-policies.
- 15. Wiley. Best practice guidelines on research integrity and publishing ethics [Internet]. Wiley; c2023 [cited 2023 Jul 8]. Available from: https://authorservices.wiley.com/ethicsguidelines/index.html.
- 16. American Association for the Advancement of Science (AAAS). Science journals: editorial policies [Internet]. AAAS; c2023 [cited 2023 Jul 8]. Available from: https://www.science.org/content/page/science-journals-editorial-policies.
- 17. ChatGPT. Why ChatGPT should not be used to write academic scientific manuscripts for publication. Ann Fam Med 2023;Mar. 20. [Epub]. https://doi.org/10.1370/afm.2982. Article
- 18. Nori H, King N, McKinney SM, Carignan D, Horvitz E. Capabilities of GPT-4 on medical challenge problems [Preprint]. Posted 2023 Apr 12. arXiv:2303.13375v2. https://doi.org/10.48550/arXiv.2303.13375. Article
- 19. Park S, Park J, Ahn J. Potential applications and implications of GPT-4 in legal inference using Korean Legal Aptitude Test (LEET). J Law Econ Regul 2023;16:7-28.https://doi.org/10.22732/CeLPU.2023.16.1.7. Article
- 20. Katz DM, Bommarito MJ, Gao S, Arredondo P. GPT-4 passes the bar exam. SSRN 2023;https://doi.org/10.2139/ssrn.4389233. Article
- 21. Baek M. A study on the assessment of Korean language proficiency of ChatGPT: focusing on the reading section of TOPIK and idioms. Lang Fact Perspect 2023;59:279-308.https://doi.org/10.20988/lfp.2023.59..279. Article
- 22. Kwon SK, Lee YT. Investigating the performance of generative AI ChatGPT’s reading comprehension ability. J Kor Eng Educ Soc 2023;22:147-72.http://dx.doi.org/10.18649/jkees.2023.2.147.
- 23. Fijačko N, Gosak L, Štiglic G, Picard CT, Douma MJ. Can ChatGPT pass the life support exams without entering the American heart association course? Resuscitation 2023;185:109732. https://doi.org/10.1016/j.resuscitation.20109732. ArticlePubMed
- 24. Huh S. Are ChatGPT’s knowledge and interpretation ability comparable to those of medical students in Korea for taking a parasitology examination?: a descriptive study. J Educ Eval Health Prof 2023;20:1. https://doi.org/10.3352/jeehp.2023.20.1. ArticlePubMedPMC
- 25. Suchman K, Garg S, Trindade AJ. Chat Generative Pretrained Transformer fails the multiple-choice American College of Gastroenterology self-assessment test. Am J Gastroenterol 2023;118:2280-2.https://doi.org/10.14309/ajg.0000000000002320. ArticlePubMed
- 26. Cai LZ, Shaheen A, Jin A, et al. Performance of generative large language models on ophthalmology board-style questions. Am J Ophthalmol 2023;254:141-9.https://doi.org/10.1016/j.ajo.2023.05.024. ArticlePubMed
- 27. Munoz-Zuluaga C, Zhao Z, Wang F, Greenblatt MB, Yang HS. Assessing the accuracy and clinical utility of ChatGPT in laboratory medicine. Clin Chem 2023;69:939-40.https://doi.org/10.1093/clinchem/hvad058. ArticlePubMed
- 28. Zhou J, Li T, Fong SJ, Dey N, Crespo RG. Exploring ChatGPT’s potential for consultation, recommendations and report diagnosis: gastric cancer and gastroscopy reports’ case. Int J Interact Multimed Artif Intell 2023;8:7-13.https://doi.org/10.9781/ijimai.2023.04.007. Article
- 29. Ayers JW, Poliak A, Dredze M, et al. Comparing physician and artificial intelligence chatbot responses to patient questions posted to a public social media forum. JAMA Intern Med 2023;183:589-96.https://doi.org/10.1001/jamainternmed.2023.1838. ArticlePubMed
- 30. Zhu L, Mou W, Chen R. Can the ChatGPT and other large language models with internet-connected database solve the questions and concerns of patient with prostate cancer and help democratize medical knowledge? J Transl Med 2023;21:269. https://doi.org/10.1186/s12967-023-04123-5. ArticlePubMedPMC
- 31. Johnson SB, King AJ, Warner EL, Aneja S, Kann BH, Bylund CL. Using ChatGPT to evaluate cancer myths and misconceptions: artificial intelligence and cancer information. JNCI Cancer Spectr 2023;7: pkad015; https://doi.org/10.1093/jncics/pkad015. ArticlePubMed
- 32. Levin G, Meyer R, Yasmeen A, et al. Chat generative Pretrained Transformer: written obstetrics and gynecology abstracts fool practitioners. Am J Obstet Gynecol MFM 2023;5:100993. https://doi.org/10.1016/j.ajogmf.2023.100993. ArticlePubMed
- 33. Bhattacharyya M, Miller VM, Bhattacharyya D, Miller LE. High rates of fabricated and inaccurate references in ChatGPT-generated medical content. Cureus 2023;15:e39238. https://doi.org/10.7759/cureus.39238. ArticlePubMedPMC
- 34. Gao CA, Howard FM, Markov NS, et al. Comparing scientific abstracts generated by ChatGPT to real abstracts with detectors and blinded human reviewers. NPJ Digit Med 2023;6:75. https://doi.org/10.1038/s41746-023-00819-6. ArticlePubMedPMC
- 35. Gupta R, Herzog I, Najafali D, Firouzbakht P, Weisberger J, Mailey BA. Application of GPT-4 in cosmetic plastic surgery: does updated mean better? Aesthet Surg J 2023;43:NP666-9.https://doi.org/10.1093/asj/sjad132. ArticlePubMed
References
Figure & Data
References
Citations
Citations to this article as recorded by 
 PubReader
PubReader ePub Link
ePub Link Cite
Cite