Creating Journal Article Tag Suite extensible markup language from Japanese language articles and automatic typesetting using extensible stylesheet language transformations
Article information

Abstract
A Japanese-language journal has been converted into the Journal Article Tag Suite (JATS) extensible markup language (XML) format, and typeset automatically via XSL formatting objects (XSL-FO) to produce both the printed issues and online journals which are published on the J-STAGE e-journal platform in full-text hypertext markup language. As there is no established XML workflow tools available for Japanese language journals, the Nakanishi Printing Company has developed its own workflow using Antenna House (AH) Formatter. AS scientific, technical, and medical journals are by-and-large in international standards even in Japanese-language, typesetting is fairly straightforward. Still, there are several challenges in processing agglutinative languages which are common in Asian counties such as Japanese, such as identifying family names/given names in a name string, or inserting “Zero Width Joiner” to avoid unfavorable line breaks. Also we had to develop individual extensible stylesheet language transformations (XSLT) for each article to position tables and figures rightly. As we go on and work with humanities journals we should face more challenges.
Introduction
Not all research articles are written in English. In countries other than English-speaking ones, higher education and scientific researchers are conducted in their native tongue and thus articles are submitted in nonEnglish languages. Such articles are not even using Latin alphabets, but Chinese characters, Korean Hangul, or Thai alphabets, for example.
According to the study conducted by the National Institute of Science and Technology Policy, the ratio of scientific, technical, and medical (STM) articles in Japanese were 25.6%. J-STAGE, an E-journal platform operated by the Japan Science and Technology Agency, published 29,813 Japanese-language journal articles vs. 17,182 English-language ones in 2013, i.e., 63.7% were in Japanese. In addition, most of the humanity/social science research articles, which are typically published in university journals, are naturally in Japanese rather than in English. Searching NDL-OPAC which contains various articles published in Japan, revealed that there were 47,888 university journal articles in Japanese in 2013 while 5,048 in English, i.e., 90.4% are in Japanese [1].
As Journal Article Tag Suite (JATS) 0.4 (formerly National Library of Medicine [NLM] document type definition [DTD] 3.1) introduced so-called multi-language capability in early 2011 [2], it has been possible to tag such Japanese-language research articles using JATS. J-STAGE now officially supports JATS 0.4, and encourage publishers to load their papers in JATS.
Multi-language Articles on J-STAGE
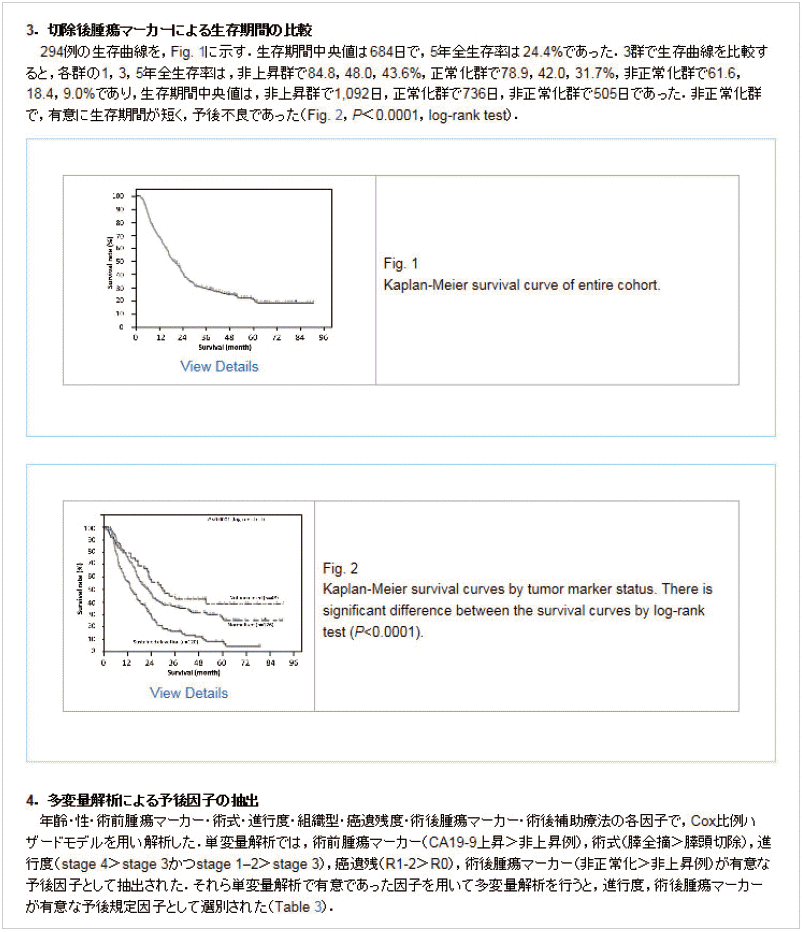
The first such journal in JATS that appeared on J-STAGE was the Japanese Journal of Gastroenterological Surgery (JJGS) [3]. Figs. 1 and 2 show top pages of a sample article in Japanese and in English. J-STAGE has a toggle feature for readers to switch between a Japanese page and English page to take advantage of this. Fig. 3 shows its body text page of this article. Although the body texts are in Japanese (Kanji and Kana) for this article, figure captions are presented in English to help international readers to get the idea such as Figs. 1 and 2.
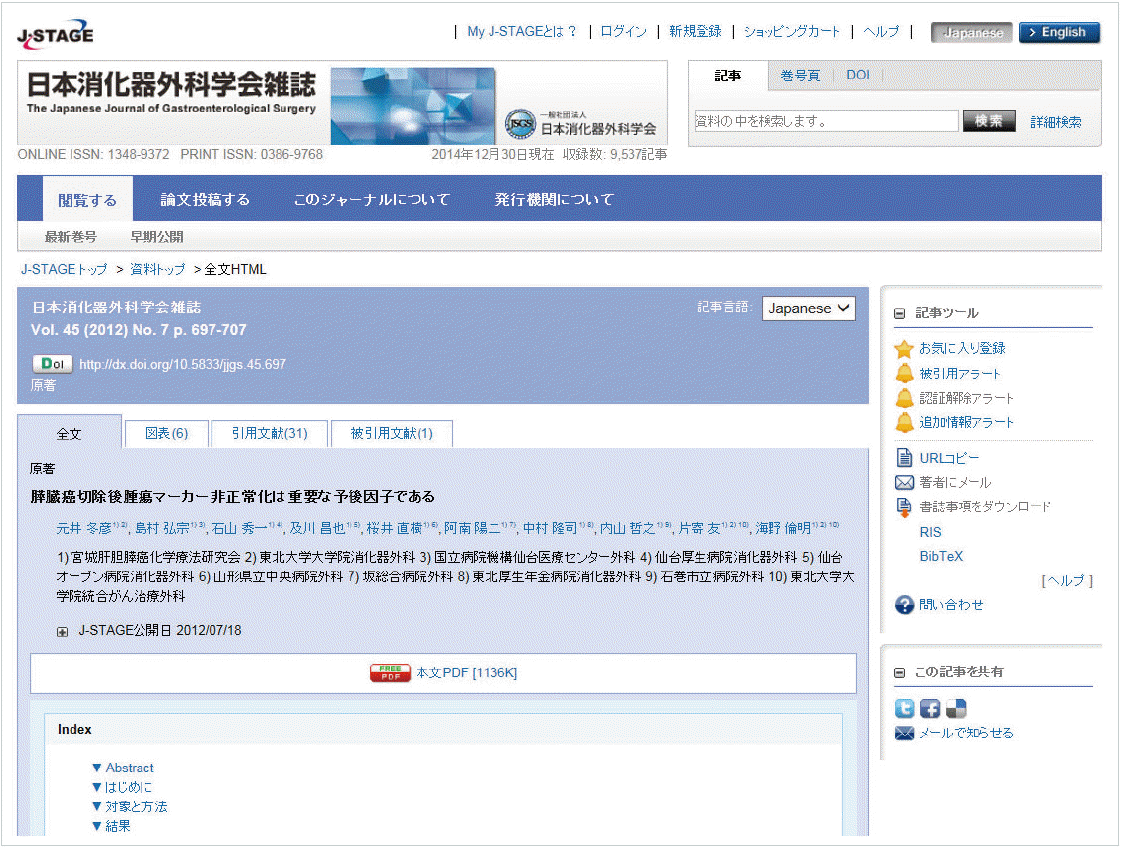
A sample article page of the Japanese Journal of Gastroenterological Surgery on J-STAGE in Journal Article Tag Suite (JATS). Available from: https://www.jstage.jst.go.jp/browse/jjgs/45/7/_contents/-char/ja/.

Also, article titles, author names and affiliations, abstracts and keywords are prepared both in Japanese and in English. Such multi-language presentation of article meta data is coded using corresponding “alternatives” tags such as <name-alternatives> of JATS (Fig. 4). NLM-DTD allowed to repeat the <name> tag, for example, so that it was possible to code multiple expressions of a single name in different languages. But such practice did not clearly show that such multiple expressions belong to a single person or to different person. A wrapper, such as the <name-alternatives> tag finally allowed us to distinguish such cases.

A sample multi-language expression using <name-alternatives>.
In the example of Fig. 4, an author name is expressed, one in Japanese as: “中西” and “秀彦,” and another in English as “Nakanishi” and “Hidehiko.” The language of the element value is defined using “xml:lang.” J-STAGE asks publishers to use the value “en” and “ja-Jpan” for “xml:lang”. The list of such “alternatives” we use are in Table 1. For elements which do not need such disambiguation, such as <abstract> and <kwd-group>, simply repeating such elements with different language attributes are sufficient. As <article title> and <subtitle> have to be unique to an article, <trans-title> and <trans-subtitle> are used to express alternate language data (Fig. 5).

Tags for multi-language expression in Journal Article Tag Suite (JATS)

Workflow of Creating Japanese XML Articles in JATS
It is a challenge to create extensible markup language (XML) data from author manuscripts, typically written in Microsoft Word. For English-language articles, eXtyles provided by Inera Inc. is a standard tool to convert a Word file into a JATS XML file for many publishers. Others use offshore vendors to convert word/pdf files to XML. Unfortunately, eXtyles is not convenient enough for Japanese-languge artilces, nevertheless there is no other readily available system for Japanese texts. Thus publishers and type-setters have been coping with this challenge.
Several approaches were implemented in Japan as follows: 1) output MS Word XML and convert it to JATS XML; 2) use eXtyles and then manually edit the result XML; 3) paste text to FrameMaker, export XML, and convert it to JATS XML; 4) ask offshore venders to create XML.
In the case of JJGS, the typesetter, Nakanishi Printing Company, has developed its own workflow to create XML as follows: 1) converting Microsoft Word to Microsoft Office Open XML; 2) converting Microsoft Office Open XML to JATS XML; 3) validating XML.
Converting Microsoft Word to Microsoft Office Open XML
Microsoft Office Open XML is a XML-based file format developed by Microsoft to represent, and its converter can translate into an XML file from MS Word [4]. A Word file is styled in advance to enhance the correct XML tagging. As the tag set of Office Open XML is very generic, it can export charts and tables (spreadsheets) as containers into XML (Fig. 6).

An example of Microsoft Office Open XML tags.
Converting Microsoft Office Open XML to JATS XML
The output XML file then goes through extensible stylesheet language transformations (XSLT) to remove unnecessary tags introduced by the Open XML converter. The resulted file is further processed by a Perl program to insert tags as defined by JATS. For English-language articles, it is possible to identify objects such as author names or journal titles fairly obviously, by looking at typeface such as bold faces or italics, or punctuation such as colons or periods. We have to insert word separators manually, especially for author names.
Agglutinative languages, such as Japanese or Korean, are characterized by the attaching of stems and affixes to form longer words to express term conjugation. In Japanese and Korean, this results in completely “agglutinated” sentences with no word separators such as spaces. In Japanese, word separation shall be achieved by identified nouns, e.g., which are in Chinese characters (Kanji) most of the time, and/or using dictionaries, or just manually.
To identify elements for article metadata, we insert separators manually. This is especially the case for author names and affiliations. Japanese author names are often expressed as a combined string, where a surname, e.g., “中西”, and a given name, e.g., “秀彦”, are attached as “中西秀彦.” To tag a such name string, we need to insert a separator manually, e.g., “中 西@秀彦,” because, it could be a combination of “中” and “西 秀彦,” or “中西秀” and “彦,” and there is no algorithm to determine it correctly. We only know this by experience, or by asking the author himself/herself. Fig. 7 shows an example of author names with separators. Identifying elements is also have an issue for citations. Family names and given names are almost always not separated, and have to be manually marked for separation. In addition, identifying article titles and journal names have to be done manually.

Example of inserted separators.
Validating XML
The result XML is then validated using the Oxygen XML editor, and the final JATS XML is obtained. It will be uploaded onto J-STAGE, and published as full text hypertext markup language (HTML) data. The quality of the article is checked using the preview feature of J-STAGE.
Creating PDF
Using AH formatter
Although JJGS is not published in print, there are strong needs to view articles in PDF. Figs. 8 and 9 show a portable document format (PDF) image corresponding to the HTML in Figs. 1 and 3 respectively. Such PDFs are created by using AH Formatter [5] from Antenna House. We have developed XSLT for this tool. An example is in Fig. 10. The XSLT converts a JATS file into XSL formatting objects (XSL-FO) which expresses page model format for PDF. The XSL-FO is then converted to PDF using the AH Formatter. The result PDF is used for proofreading by the editorial office and authors. Any proofs will be reflected to the original XML, or modifying the XSLT.


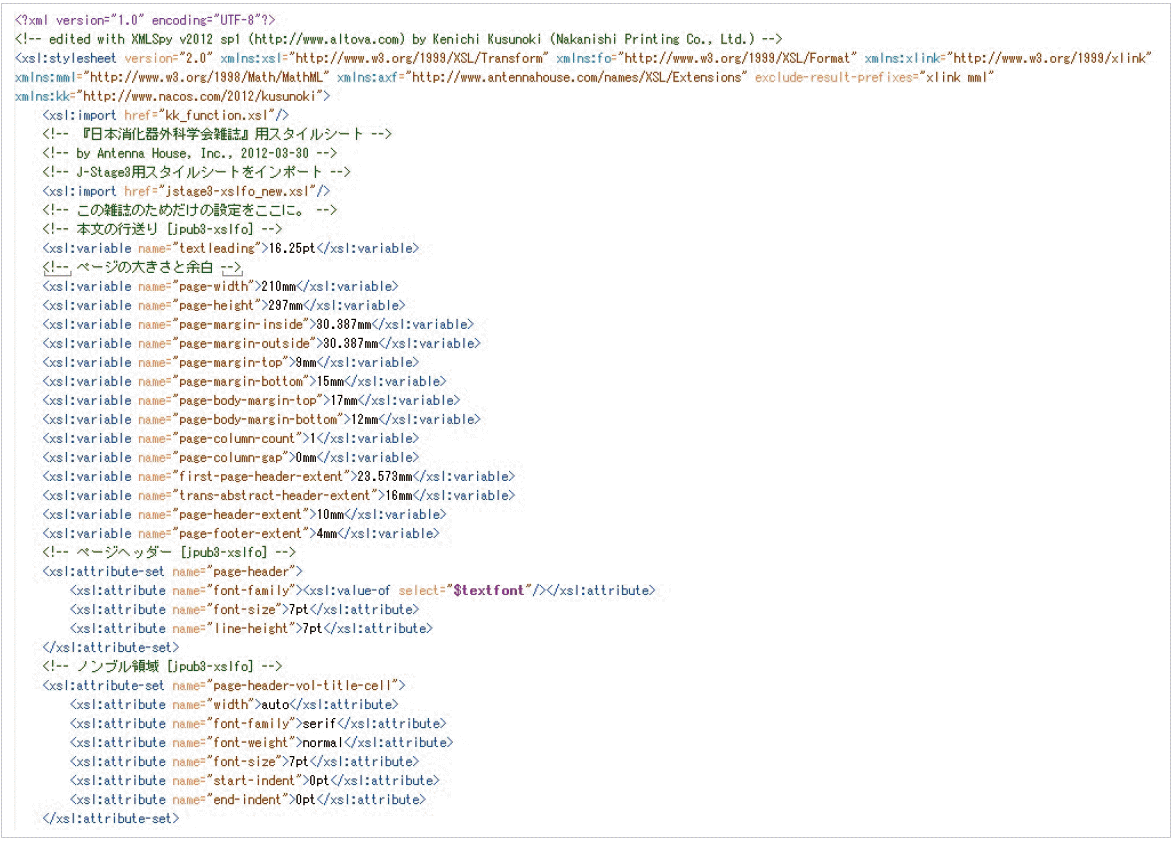
extensible stylesheet language transformations (XSLT) used for Antenna House (AH) Formatter.
Special care needed
PDF files thus created are mostly good as long as STM papers are concerned, as they are basically in the same/similar format as the corresponding western articles. UTF-8, which is the standard character encoding for XML, also enables to express most Japanese characters correctly. Still we have the following problems.
Avoid punctuations, geminate consonants, and dashes at the top of a line
Although Japanese texts do not use hyphenation of words, we have rules applicable to line breaks.
This type of rules may be handled by the formatter such as AH Formatter (Fig. 11).

Avoiding line-top punctuations (“」”).
Avoiding breaking-up a word, especially person’s names
This can only be achieved inserting “Zero Width Joiner” code ( ) in between such as “中西” in advance. This practice causes a drawback where text searching of “中西” fails (Fig. 12).

Avoiding breakups of certain words (“中西” is a person’s family name).
Positioning figures and tables
It is also necessary to develop separate XSLTs to process figures and tables in order to create acceptable PDF, which may be the case even for English-language articles published in Japan. An example of such XSLT is shown in Fig. 13. This is because Japanese authors/publishers ask the location of figures/tables exactly where they wanted they should be, rather than where the Formatter automatically located. This requires a lot of manual processing, which certainly raises cost. We, typesetters, have been trying to persuade authors and publishers [6], but not very successful so far.

Sample extensible stylesheet language transformations (XSLT) for figures.
What Are To Be Done Next
So far, what we need to process are STM articles which are written in standard, western way, and the difficulties we face are limited. In the future, we need to deal with social science/humanities literature, which are more traditional and contain the following characteristics.
Vertical writing
Although this itself does not require any special treatment in JATS tagging, automatic typesetting is not easy. Vertical writing does not simply mean aligning characters vertically (Fig. 14). For example, in writing Arabic numerals or Latin alphabets vertically, there are orientation options such as, 1) to rotate them (left), 2) not to rotate (center), and 3) to use Chinese numerals (right) as in Fig. 15. This means we need to declare writing direction when we create an XML file, such as <writing-direction type-of-direction= ”vertical”>. We do not have such a tag in JATS yet.

Horizontal vs. vertical writing.

Various patters for vertical writing.
Emphasis or Kenten
Emphasis is an extension of boldface or italics, which is often seen in Japanese articles (Fig. 16). It is not yet supported by JATS.

Examples of emphases.

Conclusion
Writing is a culture. Historically, Japanese writing and typesetting, as well as those of China and Korea, were extremely conscious of visual effect. This is probably because we use pictograph/ideograph writing system. This explains the fact that calligraphy has been so popular and advanced in those far eastern Asian countries. Thus authors and publishers care about a page layout heavily, even if the page consists of texts only. In describing texts in XML, sometimes it is necessary to code such layout information as Warichu. Maybe we should focus on semantics of Warichu, that is an inserted note, rather than its style, but we have to think. As we go further into traditional Japanese-language papers, we will discover more issues, which may or may not be solved by extending JATS.
Notes
Hidehiko Nakanishi and Tsuyoshi Yamamoto are President and staff of Nakanishi Printing Company Limited, Kyoto, Japan respectively. Toshiyuki Naganawa is a staff of Antenna House Inc., Tokyo, Japan. This article is for research purpose not for advertisement of co-authors’ companies.